Алгоритмы Data Fusion, которые применяются в реальных бизнес-кейсах и бизнес-процессах.
Основные тренды в Объединении данных и машинном обучении в предприятиях
Hype cycle for AI
Цикл состоит из 5 частей
1 Триггер инноваций - первичное появление идей в новых областях
2 Пик раздутых ожиданий/ажиотажа – ожидания выше возможностей
3 Появление разочарования – осознание реальности и возможностей проектов
4 Понимание применения
5 Развитие конкретных идей в реализацию – до этого периода доходят ~ 20 % организаций
Синтетические данные – класс данных, производимые с помощью машинного обучения и симуляции возможных ситуаций с целью снизить уровень неопределённости. (текст, изображения, табличные массивы данных)
Полуфабрикаты данных или управляемые представления данных
- позволяют соблюдать законодательные ограничения и privacy клиентов
- сохраняют максимальную ценность для задач моделирования
- эффективно "распределяют" компетенции команд
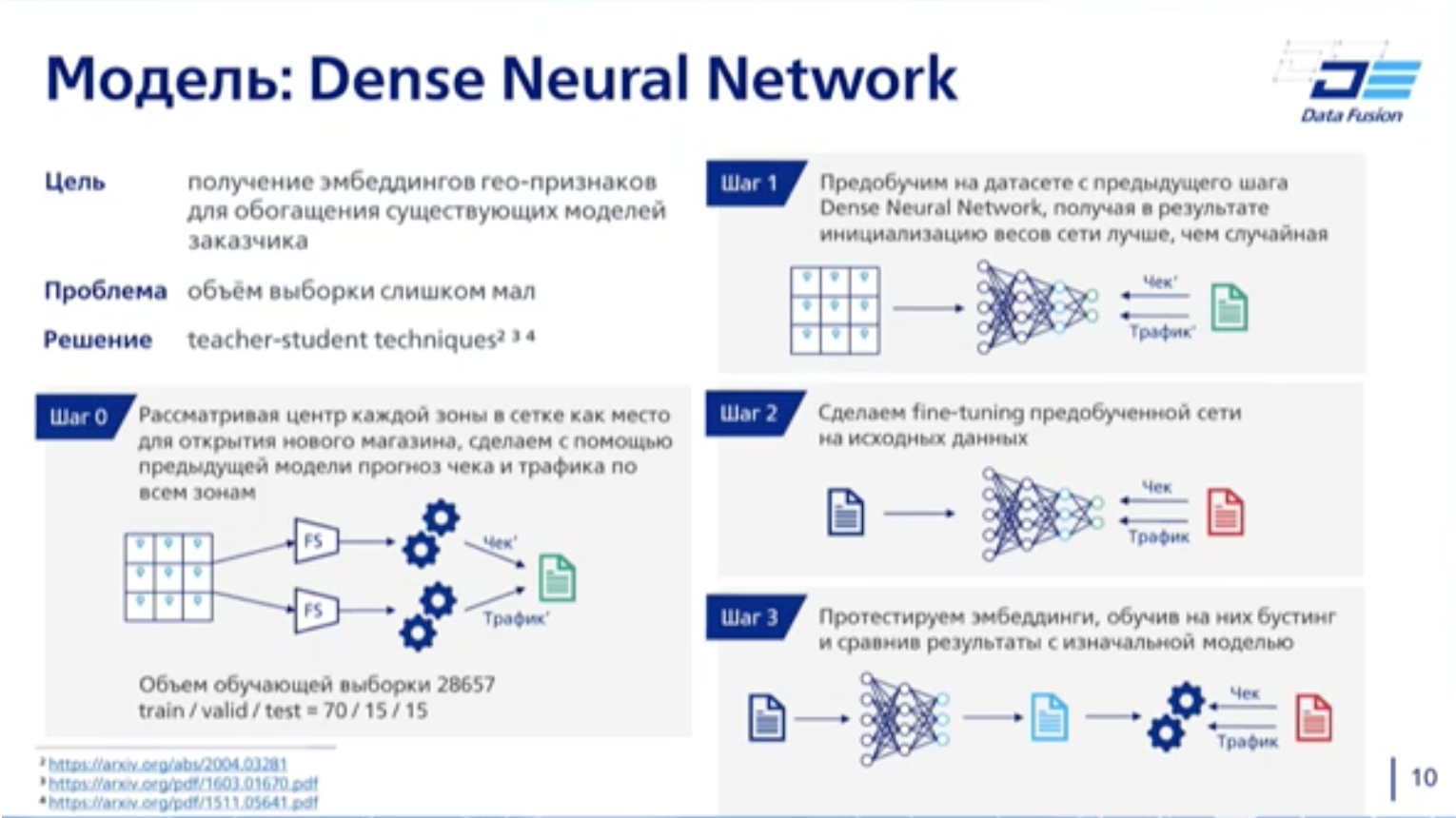
Mao-matching - способ взять исходные данные и соединить это с граф-дорогами. Точный метод определения наиболее вероятного маршрута передвижения людей в сети GSM, приземлённый на географическую карту с помощью использования графа транспортной сети.
1 фактор - отдаленность вершины от базовой станции в момент регистрации
2 фактор - расстояние между вершинами, между которыми произошло перемещение
Защищённые обезличенные данные
Embedding – представление входных данных в виде вектора чисел фиксированного размера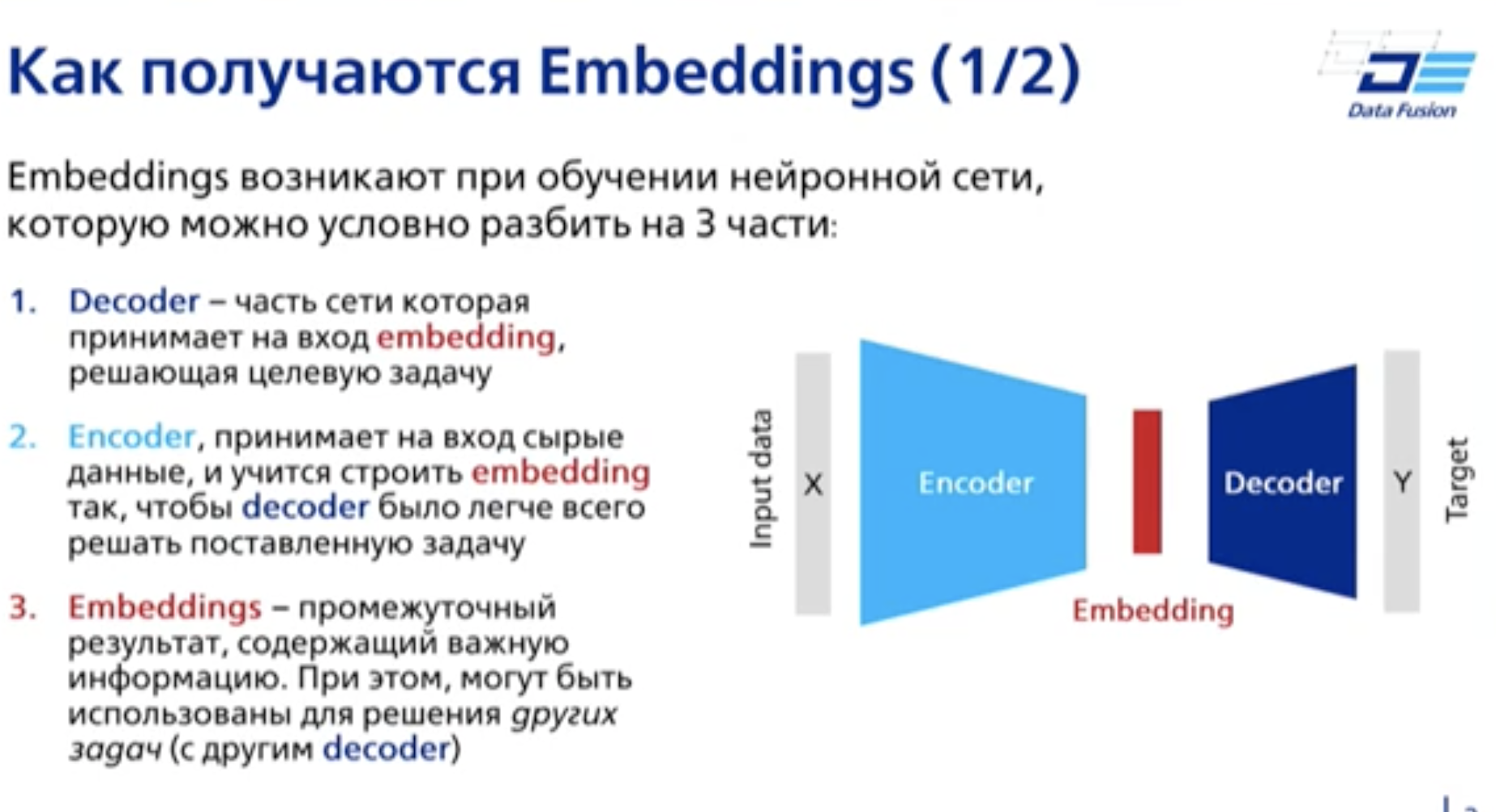
Вопросы, появившиеся после просмотра:
- Как программно реализуются нейроны?
- Как реализуются связи между нейронами?
- Как можно применить эти технологии при распознавании лиц в реальном времени при недостаточном количестве данных? Как будут использоваться синтетические данные?
- Как можно попробовать самому создать синтетические данные?
- Будет ли полезно небольшое количество синтетических данных?