Ссылка на GitHub с исходными данными и готовым проектом
1. Необходимо установить python
2. Для работы с pdf-файлами нам понадобится установить следующие пакеты через командную строку (Windows):
pip3 install pypdf2 pip3 install pymupdf pip3 install pdfrw
3. Далее создаем библиотеку для удобства хранение результатов работы
Чтение и разбор
4. Извлечение текста с помощью PyPDF2
Создадим и запустим следующий скрипт:
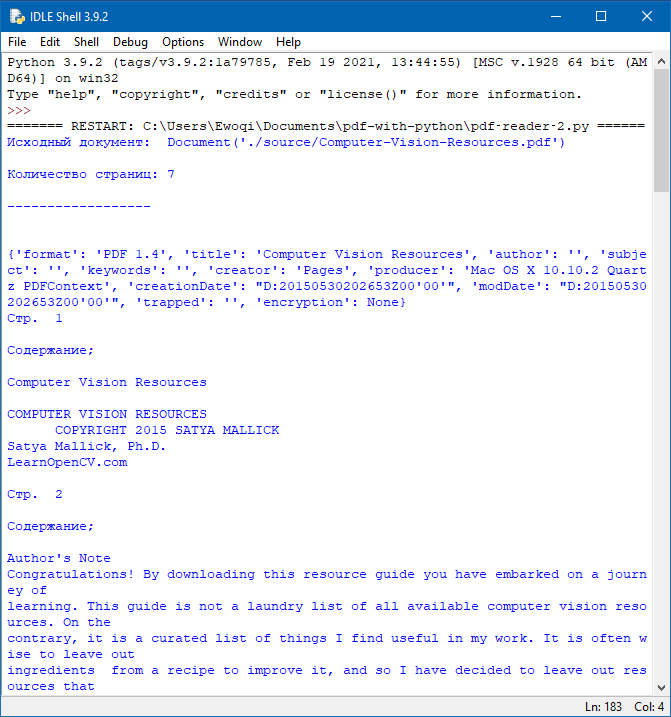
from PyPDF2 import PdfFileReader
pdf_document = "source/Computer-Vision-Resources.pdf"
with open(pdf_document, "rb") as filehandle:
pdf = PdfFileReader(filehandle)
info = pdf.getDocumentInfo()
pages = pdf.getNumPages()
print("Количество страниц в документе: %i\n\n" % pages)
print("Мета-описание: ", info)
for i in range(pages):
page = pdf.getPage(i)
print("Стр.", i, " мета: ", page, "\n\nСодержание;\n")
print(page.extractText())
В результате получаем следующее:
5. Извлечение текста с помощью PyMuPDF
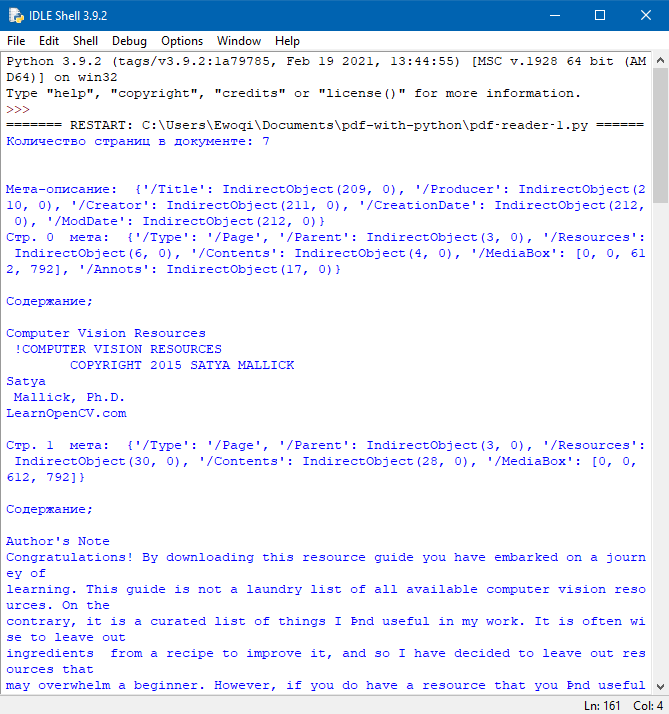
import fitz
pdf_document = "./source/Computer-Vision-Resources.pdf"
doc = fitz.open(pdf_document)
print("Исходный документ: ", doc)
print("\nКоличество страниц: %i\n\n------------------\n\n" % doc.pageCount)
print(doc.metadata)
for current_page in range(len(doc)):
page = doc.loadPage(current_page)
page_text = page.getText("text")
print("Стр. ", current_page+1, "\n\nСодержание;\n")
print(page_text)
6. Извлечение изображений из PDF с помощью PyMuPDF
import fitz
pdf_document = "source/Computer-Vision-Resources.pdf"
doc = fitz.open(pdf_document)
print("Исходный документ", doc)
print("\nКоличество страниц: %i\n\n------------------\n\n" % doc.pageCount)
print(doc.metadata)
page_count = 0
for i in range(len(doc)):
for img in doc.getPageImageList(i):
xref = img[0]
pix = fitz.Pixmap(doc, xref)
pix1 = fitz.Pixmap(fitz.csRGB, pix)
page_count += 1
pix1.writePNG("images/picture_number_%s_from_page_%s.png" % (page_count, i+1))
print("Image number ", page_count, " writed...")
pix1 = None
7. Разделение PDF‑файлов на страницы с помощью PyPDF2
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_document = "source/Computer-Vision-Resources.pdf"
pdf = PdfFileReader(pdf_document)
for page in range(pdf.getNumPages()):
pdf_writer = PdfFileWriter()
current_page = pdf.getPage(page)
pdf_writer.addPage(current_page)
outputFilename = "dist/Computer-Vision-Resources-page-{}.pdf".format(page + 1)
with open(outputFilename, "wb") as out:
pdf_writer.write(out)
print("created", outputFilename)
8. Поиск страниц на наличие заданного текста
import fitz
filename = "source/Computer-Vision-Resources.pdf"
search_term = "COMPUTER VISION"
pdf_document = fitz.open(filename)
for current_page in range(len(pdf_document)):
page = pdf_document.loadPage(current_page)
if page.searchFor(search_term):
print("%s найдено на странице %i" % (search_term, current_page+1))
Добавление изображений и водяных знаков
9. Добавлению водяного знака с помощью PyPDF2
# Добавление водяного знака в одностраничный PDF
import PyPDF2
input_file = "source/Computer-Vision-Resources.pdf"
output_file = "dist/Computer-Vision-Resources-page-drafted.pdf"
watermark_file = "source/mshe-logo-512x512.pdf"
with open(input_file, "rb") as filehandle_input:
# читать содержимое исходного файла
pdf = PyPDF2.PdfFileReader(filehandle_input)
with open(watermark_file, "rb") as filehandle_watermark:
# читать содержание водяного знака
watermark = PyPDF2.PdfFileReader(filehandle_watermark)
# получить первую страницу оригинального PDF
first_page = pdf.getPage(0)
# получить первую страницу водяного знака PDF
first_page_watermark = watermark.getPage(0)
# объединить две страницы
first_page.mergePage(first_page_watermark)
# создать объект записи PDF для выходного файла
pdf_writer = PyPDF2.PdfFileWriter()
# добавить страницу
pdf_writer.addPage(first_page)
with open(output_file, "wb") as filehandle_output:
# записать файл с водяными знаками в новый файл
pdf_writer.write(filehandle_output)
10. Добавление изображения с помощью PyMuPDF
import fitz input_file = "source/Computer-Vision-Resources.pdf" output_file = "dist/Computer-Vision-Resources-page-image.pdf" barcode_file = "source/waksoft-QR-code.jpg" # определить позицию (верхний правый угол) image_rectangle = fitz.Rect(450, 170, 550, 270) # retrieve the first page of the PDF file_handle = fitz.open(input_file) first_page = file_handle[0] # добавить изображение first_page.insertImage(image_rectangle, filename=barcode_file) file_handle.save(output_file)
11. Добавление штампов с pdfrw
# Добавление QR-кода в многостраничный PDF документ
from pdfrw import PdfReader, PdfWriter, PageMerge
input_file = "source/Computer-Vision-Resources.pdf"
output_file = "dist/Computer-Vision-Resources-QR-pages.pdf"
watermark_file = "source/waksoft-QR-code.pdf"
# определяем объекты чтения и записи
reader_input = PdfReader(input_file)
writer_output = PdfWriter()
watermark_input = PdfReader(watermark_file)
watermark = watermark_input.pages[0]
# просматривать страницы одну за другой
for current_page in range(len(reader_input.pages)):
merger = PageMerge(reader_input.pages[current_page])
merger.add(watermark).render()
# записать измененный контент на диск
writer_output.write(output_file, reader_input)
Вставка, удаление и изменение порядка страниц
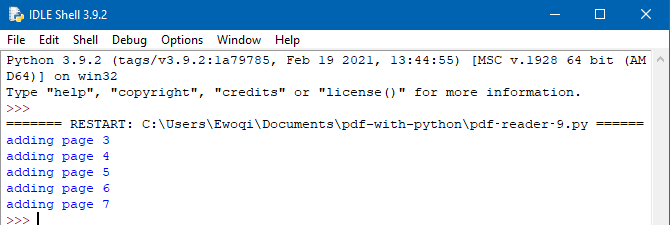
12. Удаление страниц с помощью pdfrw
# Удалите первые две страницы (титульный лист) из PDF
from pdfrw import PdfReader, PdfWriter
input_file = "source/Computer-Vision-Resources.pdf"
output_file = "dist/example-updated.pdf"
# Определить объекты чтения и записи
reader_input = PdfReader(input_file)
writer_output = PdfWriter()
# Перейти на страницу один за другим
for current_page in range(len(reader_input.pages)):
if current_page > 1:
writer_output.addpage(reader_input.pages[current_page])
print("adding page %i" % (current_page + 1))
# Записать измененный контент на диск
writer_output.write(output_file)
13. Удаление страниц с помощью PyMuPDF
# Напомним, что PyMuPDF импортируется как fitz import fitz input_file = "source/Computer-Vision-Resources.pdf" output_file = "dist/Computer-Vision-Resources-rearranged.pdf" # Определите страницы для сохранения - 1, 2 и 4 file_handle = fitz.open(input_file) pages_list = [0,1,3] # Выберите страницы и сохраните вывод file_handle.select(pages_list) file_handle.save(output_file)
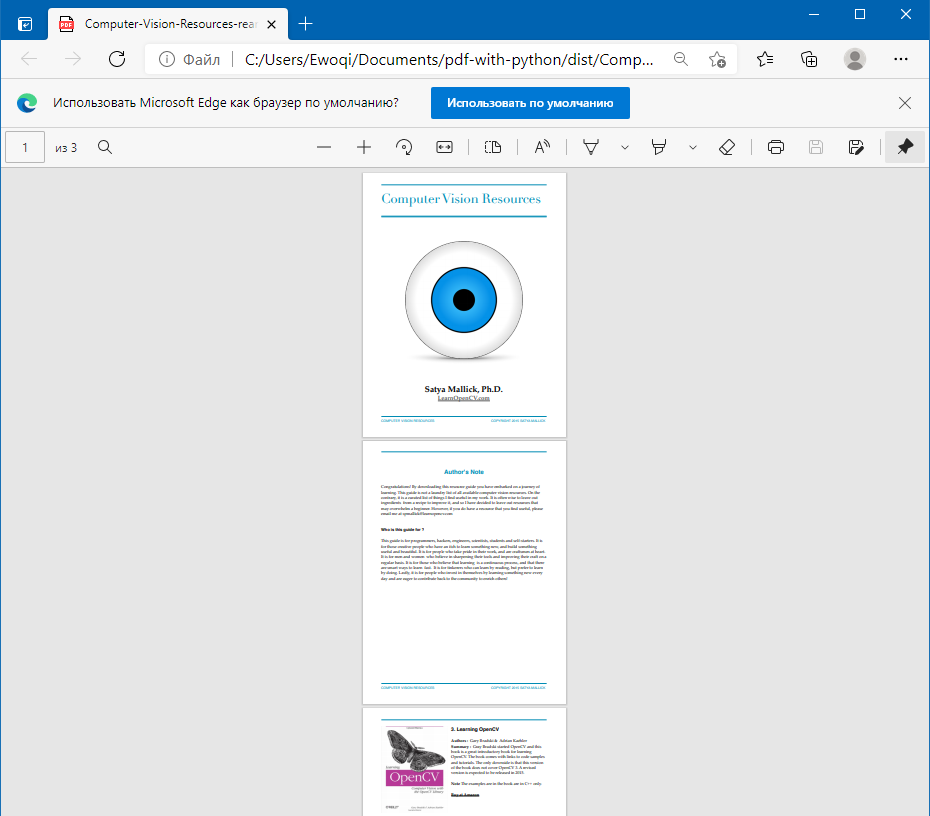
14. Вставка страниц с помощью PyMuPDF
# Напомним, что PyMuPDF импортируется как fitz import fitz original_pdf_path = "source/Computer-Vision-Resources.pdf" extra_page_path = "dist/extra-page.pdf" output_file_path = "dist/example-extended.pdf" original_pdf = fitz.open(original_pdf_path) extra_page = fitz.open(extra_page_path) original_pdf.insertPDF(extra_page) original_pdf.save(output_file_path)
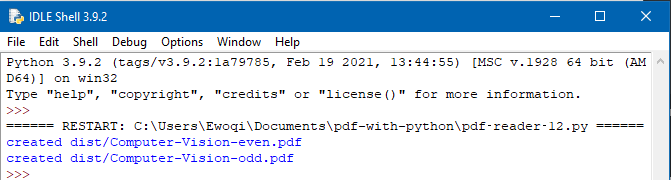
15. Разделение четных и нечетных страниц с помощью PyPDF2
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_document = "source/Computer-Vision-Resources.pdf"
pdf = PdfFileReader(pdf_document)
# Выходные файлы для новых PDF-файлов
output_filename_even = "dist/Computer-Vision-even.pdf"
output_filename_odd = "dist/Computer-Vision-odd.pdf"
pdf_writer_even = PdfFileWriter()
pdf_writer_odd = PdfFileWriter()
# Получить досягаемую страницу и добавить ее в соответствующую
# выходной файл на основе номера страницы
for page in range(pdf.getNumPages()):
current_page = pdf.getPage(page)
if page % 2 == 0:
pdf_writer_odd.addPage(current_page)
else:
pdf_writer_even.addPage(current_page)
# Записать данные на диск
with open(output_filename_even, "wb") as out:
pdf_writer_even.write(out)
print("created", output_filename_even)
# Записать данные на диск
with open(output_filename_odd, "wb") as out:
pdf_writer_odd.write(out)
print("created", output_filename_odd)