1. Запускаем Командную строку (Windows) и переходим в папку, где установлен Python
cd C:\Users\Ewoqi\AppData\Local\Programs\Python\Python39\Scripts
2. Необходимо установить следующие пакеты:
pip install numpy pip install scipy pip install pandas pip install matplotlib
3. Теперь необходимо импортировать все пакеты в свои скрипты:
import math import statistics import numpy as np import scipy.stats import pandas as pd
4. Также создадим некоторые исходные данные:
x = [8.0, 1, 2.5, 4, 28.0] x_with_nan = [8.0, 1, 2.5, math.nan, 4, 28.0] print(x) print(x_with_nan)
Результат:

5. Чтобы получить значения nan:
print(math.isnan(np.nan), np.isnan(math.nan)) print(math.isnan(x_with_nan[3]), np.isnan(x_with_nan[3]))
Результат:

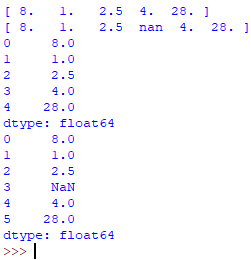
6. Далее создадим объекты np.ndarray и pd.Series, соответствующие x и x_with_nan:
y, y_with_nan = np.array(x), np.array(x_with_nan) z, z_with_nan = pd.Series(x), pd.Series(x_with_nan) print(y) print(y_with_nan) print(z) print(z_with_nan)
Результат:
Центральные метрики
1. Среднеарифметическое
7. Вычисление среднего значения на чистом Python, используя sum() и len(), без импорта библиотек:
mean_ = sum(x) / len(x) print(mean_)
Результат:
![]()
8. Вычисление среднего значения с помощью встроенных функций статистики Python
mean_ = statistics.mean(x) print(mean_) mean_ = statistics.fmean(x) print(mean_)
Результат:
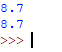
9. Однако если среди ваших данных есть значения nan, то statistics.mean() и statistics.fmean() вернутся nan в качестве результата:
mean_ = statistics.mean(x_with_nan) print(mean_) mean_ = statistics.fmean(x_with_nan) print(mean_)
Результат:
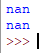
Этот результат связан с поведением sum(). Ведь sum(x_with_nan) также возвращает nan.
10. С помощью библиотеки NumPy тоже можно получить среднее значение
mean_ = np.mean(y) print(mean_)
Результат:
![]()
11. Также можно просто использовать соответствующий метод
print(y.mean())
Результат:
![]()
12. И функция, и метод ведут себя аналогично при наличии значений nan среди ваших данных, для того, чтобы игнорировать nan можно использовать метод nanmean()
print(np.mean(y_with_nan)) print(y_with_nan.mean()) print(np.nanmean(y_with_nan))
Результат:
![]()
13. Объекты pd.Series также имеют метод .mean() Pandas, который игнорирует значения nan по умолчанию
mean_ = z.mean() print(mean_) print(z_with_nan.mean())
![]()
2. Средневзвешенное
14. В чистом Python средневзвешенное можно реализовать комбинацией sum() с range() или zip()
x = [8.0, 1, 2.5, 4, 28.0] w = [0.1, 0.2, 0.3, 0.25, 0.15] wmean = sum(w[i] * x[i] for i in range(len(x))) / sum(w) print(wmean) wmean = sum(x_ * w_ for (x_, w_) in zip(x, w)) / sum(w) print(wmean)
Результат:
![]()
15. Для большого набора данных можно использовать np.average() для массивов NumPy или серии Pandas
x = [8.0, 1, 2.5, 4, 28.0] y, z, w = np.array(x), pd.Series(x), np.array(w) wmean = np.average(y, weights=w) print(wmean) wmean = np.average(z, weights=w) print(wmean)
Результат:
![]()
16. Также можно использовать поэлементное умножение w*y с np.sum() или .sum()
print((w * y).sum() / w.sum())
Результат:
![]()
17.