1. Нам необходимо предварительно установить, и затем подключить следующие библиотеки:
import pandas as pd import numpy as np import matplotlib.pyplot as plt
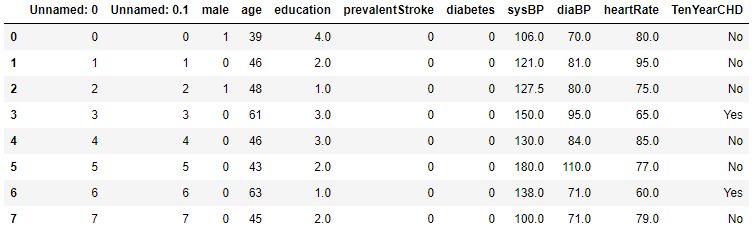
2. Далее необходимо подключить свои данные:
tall = pd.read_csv("../matveev/Data/1heart4.csv")
tall.head(8)
3. С помощью следующей команды можно узнать количество строк и столбцов:
print( "число строк =", tall.shape[0], "число столбцов =", tall.shape[1])
![]()
4. Далее проанализируем наши данные:
cols=tall.columns
for col in cols:
s=tall[col].dtypes
if s == 'object' or s == 'int64':
n=tall[col].nunique()
print(col, s, n)
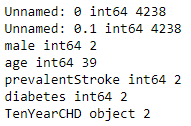
Как мы видим первые 2 столбца - это счетчики, 39 вариантов - возрастов, TenYearCHD - наша целевая переменная, с которой мы будем работать.
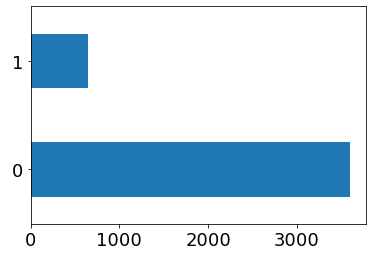
5. Далее зададим нашей целевой переменной значения типа int, и продемонстрируем их значения с помощью диаграммы:
from sklearn.preprocessing import LabelEncoder
la = LabelEncoder()
mapped_TenYearCHD = pd.Series(la.fit_transform(tall['TenYearCHD']))
mapped_TenYearCHD.value_counts().plot.barh()
plt.show()
dicts={}
dicts=dict(enumerate(la.classes_))
print(dicts)
6. Теперь посмотрим на то, как изменились данные:
tall['TenYearCHD'] = mapped_TenYearCHD tall.head(5)
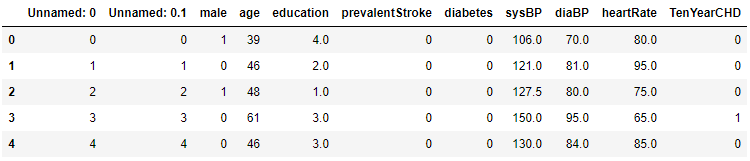
7. Далее мы можем вычислить корреляционную матрицу для данных и наглядно продемонстрировать связь между показателями:
corr=tall.corr()
import seaborn as sns
f, ax = plt.subplots(figsize=(20, 20))
sns.heatmap(corr, annot=True, mask=np.zeros_like(corr, dtype=np.bool),
cmap=sns.diverging_palette(300, 10, as_cmap=True),
square=True, ax=ax)
8. Также нам необходимо удалить дублируемый столбик:
tall = tall.drop(['Unnamed: 0.1'], axis=1)
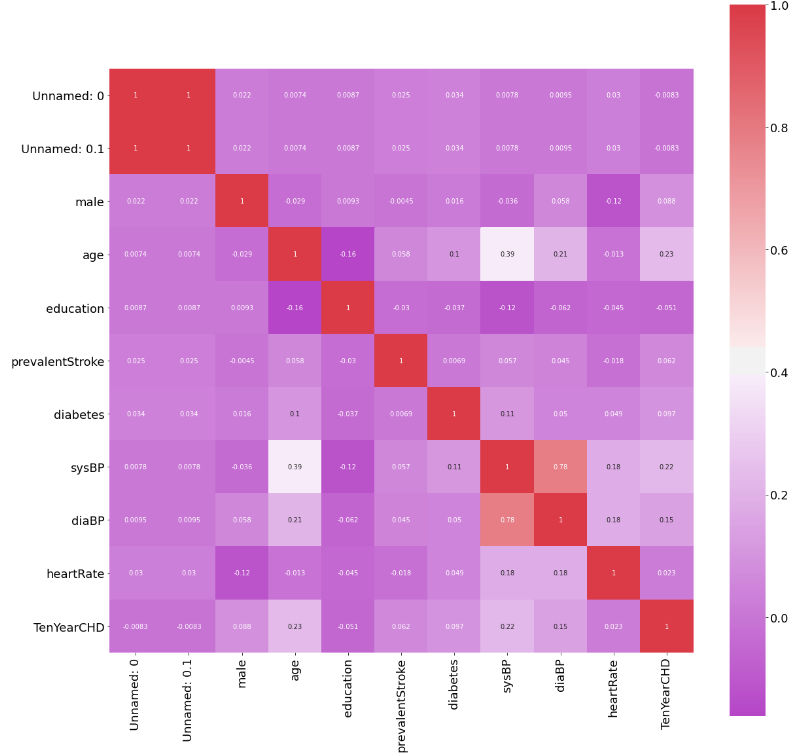
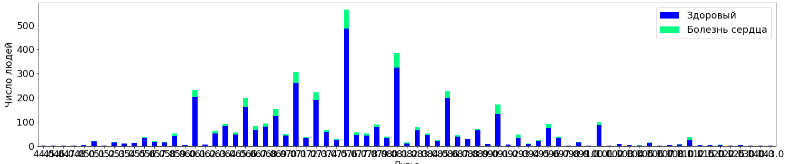
9. Далее необходимо определиться с тем, какие данные показывают зависимость:
tall_aggr1=tall.pivot_table('Unnamed: 0', 'age', 'TenYearCHD', 'count', fill_value=0)
tall_aggr1.plot(kind='bar', stacked=True, figsize=(25,5), fontsize =18, rot=0, colormap='winter')
plt.legend(labels=['Здоровый','Болезнь сердца'], fontsize=18)
plt.xlabel("Возраст", fontsize=15)
plt.ylabel("Число людей", fontsize=18)
plt.show()
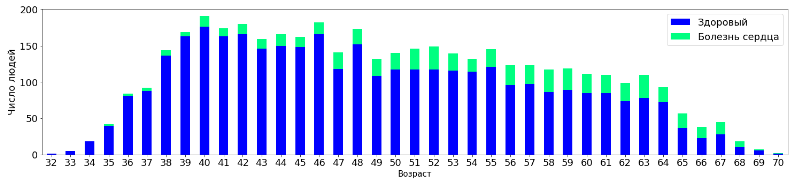
tall_aggr2=tall.pivot_table('Unnamed: 0', 'diabetes', 'TenYearCHD', 'count')
tall_aggr2.plot(kind='bar', stacked=True, figsize=(25,5), fontsize =18, rot=0, colormap='winter')
plt.legend(labels=['Здоровый','Болезнь сердца'], fontsize=18)
plt.xlabel("Диабет", fontsize=15)
plt.ylabel("Число людей", fontsize=18)
plt.show()
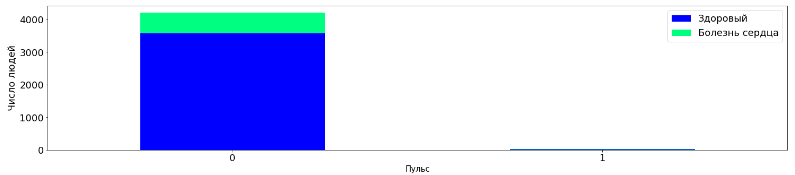
tall_aggr3=tall.pivot_table('Unnamed: 0', 'prevalentStroke', 'TenYearCHD', 'count')
tall_aggr3.plot(kind='bar', stacked=True, figsize=(25,5), fontsize =18, rot=0, colormap='winter')
plt.legend(labels=['Здоровый','Болезнь сердца'], fontsize=18)
plt.xlabel("Пульс", fontsize=15)
plt.ylabel("Число людей", fontsize=18)
plt.show()
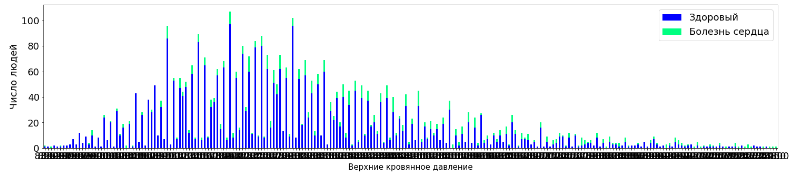
tall_aggr4=tall.pivot_table('Unnamed: 0', 'sysBP', 'TenYearCHD', 'count', fill_value=0)
tall_aggr4.plot(kind='bar', stacked=True, figsize=(25,5), fontsize =18, rot=0, colormap='winter')
plt.legend(labels=['Здоровый','Болезнь сердца'], fontsize=18)
plt.xlabel("Верхние кровянное давление", fontsize=15)
plt.ylabel("Число людей", fontsize=18)
plt.show()
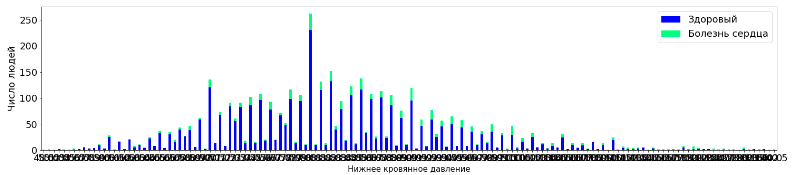
tall_aggr5=tall.pivot_table('Unnamed: 0', 'diaBP', 'TenYearCHD', 'count', fill_value=0)
tall_aggr5.plot(kind='bar', stacked=True, figsize=(25,5), fontsize =18, rot=0, colormap='winter')
plt.legend(labels=['Здоровый','Болезнь сердца'], fontsize=18)
plt.xlabel("Нижнее кровянное давление", fontsize=15)
plt.ylabel("Число людей", fontsize=18)
plt.show()
tall_aggr6=tall.pivot_table('Unnamed: 0', 'heartRate', 'TenYearCHD', 'count', fill_value=0)
tall_aggr6.plot(kind='bar', stacked=True, figsize=(25,5), fontsize =18, rot=0, colormap='winter')
plt.legend(labels=['Здоровый','Болезнь сердца'], fontsize=18)
plt.xlabel("Пульс", fontsize=15)
plt.ylabel("Число людей", fontsize=18)
plt.show()
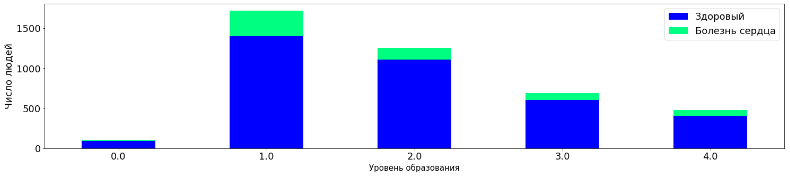
tall_aggr7=tall.pivot_table('Unnamed: 0', 'education', 'TenYearCHD', 'count', fill_value=0)
tall_aggr7.plot(kind='bar', stacked=True, figsize=(25,5), fontsize =18, rot=0, colormap='winter')
plt.legend(labels=['Здоровый','Болезнь сердца'], fontsize=18)
plt.xlabel("Уровень образования", fontsize=15)
plt.ylabel("Число людей", fontsize=18)
plt.show()
10. Также существуют ещё способы для нахождения связей, но для начала необходимо удалить 1 столбец - счетчик:
tall = tall.drop(['Unnamed: 0'], axis=1)
11. Теперь необходимо разделить выборку на тестовую и обучающую:
clDrop='TenYearCHD' ytall=tall[clDrop].values tall.drop(clDrop, axis=1, inplace=True) xtall=tall.values Mtest=int(len(tall)/4) Mtrain= int(len(tall)-Mtest) ttrain = np.arange(Mtrain) ttest = np.arange(Mtest) + Mtrain print (len(tall), Mtrain, Mtest)
![]()
12. Далее в работе идет процесс обучения:
ttrain = np.arange(Mtrain)
ttest = np.arange(Mtest) + Mtrain
print (ytall[ttrain])
from sklearn.metrics import roc_auc_score, accuracy_score, roc_curve
from sklearn import tree
dtc = tree.DecisionTreeClassifier(max_depth = 8, max_features = 8)
dtc = dtc.fit(xtall[ttrain], ytall[ttrain])
ytrainDtc = dtc.predict_proba(xtall[ttrain])
ytestDtc = dtc.predict_proba(xtall[ttest])
sc0= dtc.score(xtall[ttrain], ytall[ttrain])
sc1= dtc.score(xtall[ttest], ytall[ttest])
print("DesicionTree", "i_fold =", " Точность обучения", sc0, " Точность тестовая", sc1)
![]()
def estim(y_prob,y_exact, pr):
kall=y_prob.shape[0]
tp=0
fp=0
tn=0
fn=0
kr=0
for i in np.arange(kall):
if(y_prob[i] > pr):
if(y_exact[i] == 1 ):
tp+=1
else:
fp+=1
else:
if(y_exact[i] == 0 ):
tn+=1
else:
fn+=1
kr=1.*(tp+tn)/kall
kr1=1.*tp/(tp+fp)
kr0=1.*tn/(tn+fn)
rr1=1.*tp/(tp+fn)
rr0=1.*tn/(tn+fp)
print("Precission: ", kr0, "класс 0 Здоровы", tn+fn, " Из них правильно спрогнозировано =", tn, ", ошибочно=", fn)
print("Precission: ", kr1,"класс 1 Больны", tp+tn, " Из них правильно спрогнозировано =", tp, ", ошибочно=", tn)
print("Recall: ", rr0,"класс 0 Здоровы")
print("Recall: ", rr1,"класс 1 Больны")
print("Точность распознавания ", kr, " precission", "recall")
return kr
estim(ytestDtc[:,1], ytall[ttest], 0.5)

13. Много кода, который необходим для обучения...
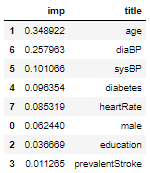
14. Метод "feature_importances", который возвращает вектор "важностей" признаков:
imp= dtc.feature_importances_
imp = dtc.feature_importances_
rfImp = pd.DataFrame(imp, columns=['imp'])
title1 = tall.columns
rfImp['title']=title1
rfImp = rfImp.sort_values('imp', ascending = False)
rfImp.head(9)
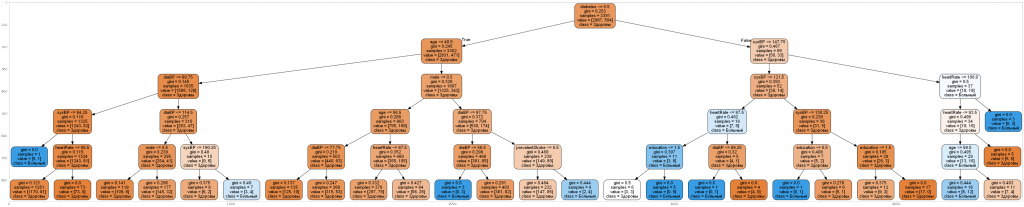
15. Теперь создадим дерево решений:
import pydotplus
dot_data = tree.export_graphviz(dtc, feature_names=title1,class_names=["Здоровы", "Больный"], out_file=None, filled=True, rounded=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_png("../matveev/DC.jpg")
import matplotlib.image as mpimg
img=mpimg.imread("../matveev/DC.jpg")
img=mpimg.imread("../matveev/DC.jpg")
fig = plt.figure(figsize=(100,100))
imgplot = plt.imshow(img)